Many of the most powerful machine learning techniques and software libraries of the last two decades have been developed by online marketing giants like Facebook or Google.
The mission of our data science team at Content Garden is to leverage the newest developments in the field to make our native advertising campaigns as successful as possible. At the same time, we believe that “even” advertising on the internet can and should value to people’s lives. The purpose of this article is to give you an overview of topics that we are currently investigating, we have already in use, or seem promising to work on in the future. In upcoming articles we will cover some of the topics in detail.
Our current data science activities can roughly be grouped into the domains of data visualization and interpretation, prediction of Key Performance Indicators (KPIs), delivery automation and optimization, and automated content selection & generation.
Data visualization and interpretation
Visualization and interpretation of data is perhaps the most classic and comprehensible discipline of data science. It is far more than creating simple scatter plots or fancy looking dashboards. Its purpose is to find explanations why a certain campaign or text may have performed exceptionally well, or why it may not have met our requirements at all. Finally, the explanations we find need to be pointed out and communicated to other, non-technical units of our company – that’s why visualizations need to be clear and beautiful. Beauty to catch attention, clarity to provide understanding.
According to the 2018 Kagge Data Science Survey, Python has become the most important data science programming language. The data science team of Content Garden has used the Python ecosystem from the very beginning, simply because it’s free (mostly), has the largest community, and integrates seamlessly to the rest of our tech stack. For visualization, we have good old matplotlib and wrappers like seaborn or pandas in heavy use, and we are beginning to adapt the concepts of the grammar of graphics using tools such as ggplot and bokeh dashboards for interactive visualization.
With regard to the notion of interpretability in machine learning, a clear definition does not exist. For us, the two key questions in this context are
- How important are the different features of a content entity to predict a certain KPI?
- Does the KPI tend to increase or decrease if the value of the feature increases/ decreases?
Before I elaborate a bit more on these two points, let me briefly make clear what is meant by ‘feature’ in this context: a feature is a property of a content entity (article, image gallery etc.) that we provide as input for the machine learning model. Features can either be numerical (e.g., the number of words in the title) or categorical (e.g., is the title a question? Does the image contain a human?). Note that the extraction of human-understandable features is an essential part of the creation of interpretable models.
Approaches to the above two points range from computing correlation coefficients over techniques like the permutation of features or sparse linear regression up to complex game-theoretic methods like the computation of Shapley values (s. Figure 1).

Figure 1: Shapley value explanation of why an image classifier has recognized a dowitcher as a dowitcher and a meerkat as a meerkat. The dowitcher was identified by its bill and dowage and the meerkat by its face. Note that the classifier did recognize the meerkat as being not a mongoose also because of its face. Source: github.com/slundberg/shap
Prediction of Key Performance Indicators
The large database of campaigns Content Garden took care of over the last years enables us to predict KPIs already before the first piece of content of a campaign goes live. More importantly, KPI prediction may be performed including content-independent features such as placement properties, daytime, or operating system of the reader. This in turn can be used to publish content exactly on placements where they presumably will perform best.
One approach is to view the problem of KPI prediction in analogy to recommender systems (s. Figure 2) that are in broad use by companies such as Netflix, Spotify, or Amazon. What if we’d rephrase popular expressions like ‘people who bought diapers also bought tissues’ or ‘people who watched “Sharknado” may also watch “Cowboys & Aliens”’ to ‘Content that performed well on placement A will also perform well on placement B’? The most popular class of recommender systems is known under the name of collaborative filtering. The benefit of such models is that no placement-specific features are needed to recommend good placements for content. The downside is the presence of the so-called cold start problem: no recommendations can be made for content that has never been published before.
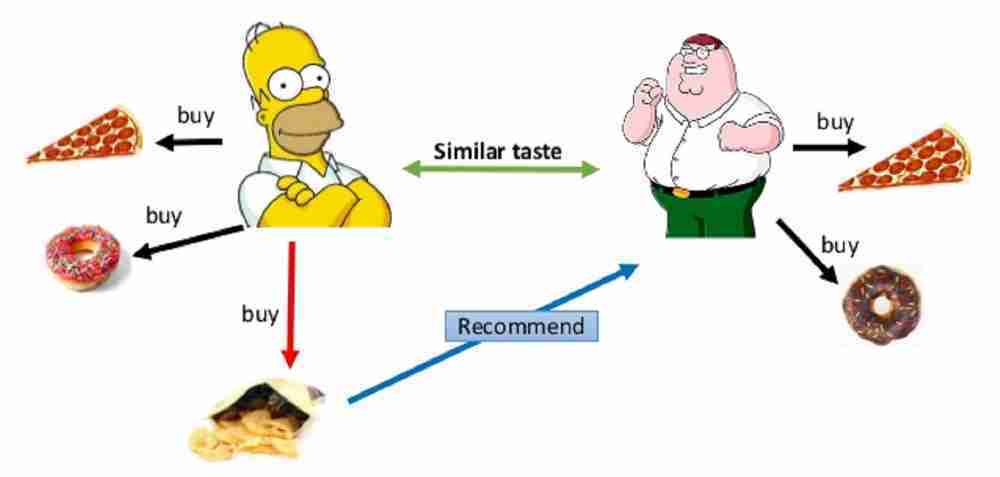
Figure 2: Visualization of a recommender system. Customers who showed the same taste in the past are likely to buy similar stuff in the future. The same system can be used to ‘recommend’ placements to teasers. Source: M. Ben Ellefi in Profile-based Dataset Recommendation for RDF Data Linking
The other important direction we are investigating in the context of KPI prediction is – of course – deep learning. In both computer vision (= processing of image data) as wells as natural language processing (NLP, = processing of text/speech data), deep learning has become the gold standard for the vast majority of problems. The word ‘deep’ in deep learning refers to their layered architecture, where the output of one layer plays the role of the input to the next layer, whose output then is the input to the next layer and so on, until the final output, the prediction of the KPI in our case, is reached. Because of rough analogies to how the human brain works (the firing of neurons is stimulating other neurons, which in turn may fire and stimulate another layer of neurons), deep learning models are called Artificial Neural Networks (ANNs).
It is said that ANNs learn their own features (which is slightly incorrect from the author’s point of view) to solve a specific task. These features are generally not graspable by a human mind, which is why it is hardly possible to explain and interpret their predictions. On the other side, this property makes ANNs particularly relevant for an approach called transfer learning. Can the features a neural network has learned to be predictive for the recognition of objects in an image be also predictive for, e.g., the click through rate (CTR) of an ad containing the image? Technically speaking, this boils down to a representation of the image in a high-dimensional space where similar images are close to each other. Finally, these embeddings are used in a so-called downstream model to predict the quantity of interest.
Delivery automation and optimization
Having models for the prediction of the various KPIs describing the performance of content entities directly raises the question of how to gain most out of it. Of course, content should be put on placements in an ad network where the predicted KPI is as high as possible. However, there are several side conditions we need to take into account. Every placement can only provide a finite amount of ad impressions per unit time, most campaigns have goals in terms of ad impressions they need to achieve, or, client may want their campaign to be published on certain media only. All these restrictions need to be met in the optimized configuration we want to find.
Moreover, to say it with the words of the great statistician George Box: “All models are wrong, but some are useful” – Even the best models for KPI prediction will contain a certain degree of error. So what if we initially believe that a teaser will perform exceptionally well, but then we let it run and it turns out that it does a very poor job? Or vice versa, what happens if we predict a pretty low KPI, but if we try out and publish the teaser, it’s working like a charm? The point is, it is not only about optimization. There must be clever trial and error and updating of what we know about the KPIs as well. To put it in more formal words, we play the role of an agent that is observing the state of a system (the configuration of active/inactive teaser-placement combinations) and performs actions based on a reward in the form of improved KPIs. This is exactly the setting of a Reinforcement Learning problem – one of the hottest fields in present-day machine learning research. It provides a natural way to update our knowledge about the KPIs using the incoming stream of data of published content.
Automated content selection & generation
An accurate and reliable prediction of content KPIs would have another interesting use case: we could couple to a ‘content reservoir’ that contains, e.g., an image database, previously used copy texts, or articles. Using the KPI prediction model, content could be suggested to the authors according to the predicted performance for a certain campaign that is created.
One may even think of generating new content in a completely automated way. The key enabler technology for this is called Generative Adversarial Network (GAN), one of the most fascinating innovations in the field of AI and machine learning over the last years. You can think of GANs as a simulated cops and robbers game consisting of a generative and a discriminative neural network. Let’s say we want to train our GAN to create fake pictures of 100$ bills. The generative part is trained so as to generate as realistically looking faked bills as possible, whereas the discriminative part is simultaneously trained such that it can classify whether a bill is fake or not. The two parts play their zero-sum game and if everything goes well (training GANs is notoriously difficult), we end up with a generator that can create realistically looking pictures of 100$ bills, whereas the discriminator is a master in filtering out the fake from the real.

Figure 3: Human faces generated by a computer using a Generative Adversarial Network. Source: A Style-Based Generator Architecture for Generative Adversarial Networks
This adversarial principle has already been used to create fake pictures of human faces (s. Figure 3), fashion, or even short video sequences. To my knowledge, GANs are the first method that allows computers to perform creative tasks. So why not use them to automatically generate, e.g., text?
Conclusion
The intention behind this article was to give you an overview of what data science implies for us in the field of native advertising. It is meant to be the start of a series of articles in which we want to go deeper into the topics that were outlined in the sections above. So stay tuned.